
Sandro
Author
Published on : Nov 15, 2016
Category : BizTalk Server
First of all, let me say thanks to Saravana for inviting me to be a guest blogger in BizTalk360 blog. I hope this will be the first of many… and why not start creating a series call “Thinking outside the box (or not)” where I will address some common scenarios, requirements, operations, features and so on, and I will provide some tips or best approaches that you can implement.
In this first post, we will address the following topic: How to properly call a SQL stored procedure without any inputs parameters?
In the last few months, I find myself migrating several projects from previous BizTalk versions to BizTalk Server 2013 R2 and revising/improving other projects. I have seen crazy ways to invoke a service or a stored procedure that doesn’t accept any inputs/parameters, for example: a stored procedure that gets all the existing codes from a SQL table.
Taking this sample, calling a stored procedure that gets all the existing codes from a SQL table, let’s see all the different approaches that I found. Why shouldn’t you do some of them and find out what’s the best approach to achieve this requirement in BizTalk Server. But be aware that all of these approaches actually work, of course, one better than others.
In this Proof-of-Concept (PoC), we have a simple SQL Server table called Codes that only contains a code identifier that is unique in the system, as you can see from the picture below and, once again, we will try to call a stored procedure that gets all the existing codes from that specific SQL table.
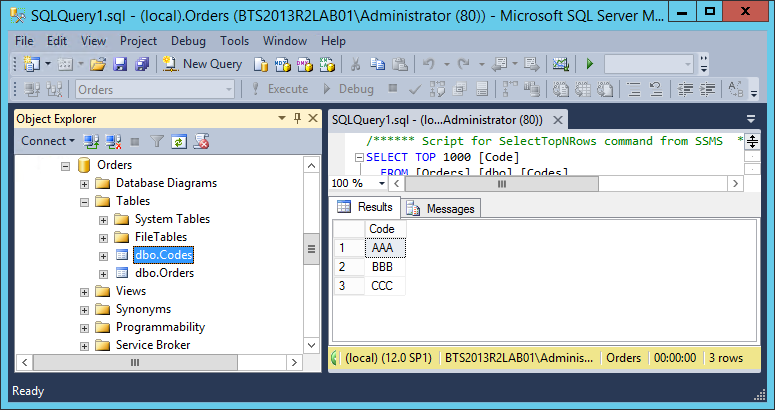
We have the following basic Stored procedure:
CREATE PROCEDURE [dbo].[usp_GetCodes]
AS
BEGIN
— SET NOCOUNT ON added to prevent extra result sets from
— interfering with SELECT statements.
SET NOCOUNT ON;
SET XACT_ABORT ON;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
— Insert statements for procedure here
SELECT Code
FROM Codes
END
For all the approaches in this PoC, basically what we will do is create an orchestration that:
So basically, all the approaches will have a similar orchestration structure:
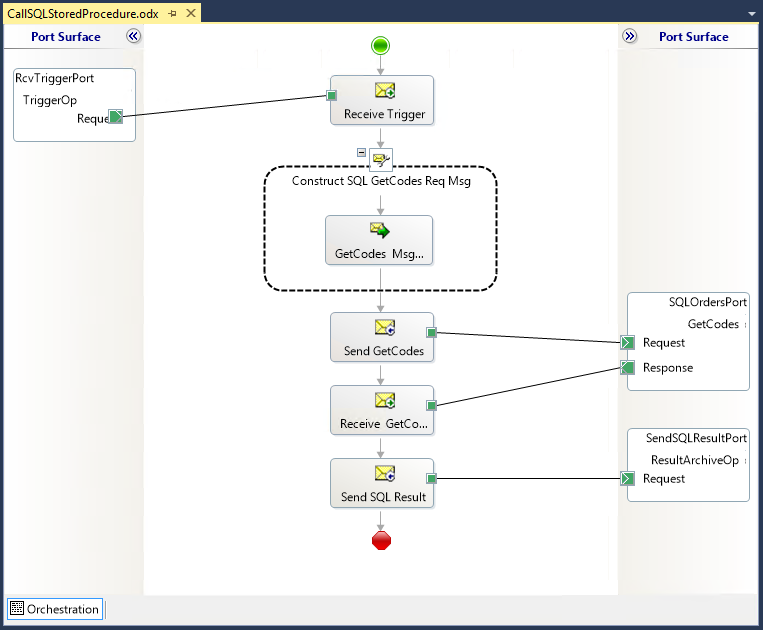
Of course, in real case scenarios, this orchestration will probably have more additional steps, like after retrieval of the codes we might retrieve additional data based on the earlier retrieved codes, filter the information or any other thing. But for this PoC let’s keep it simple.
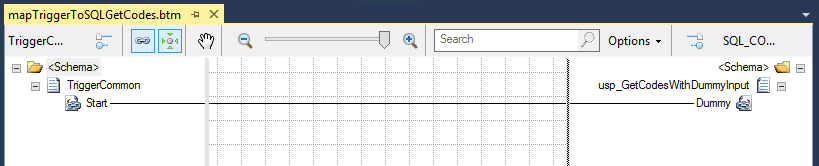
The most common approach that I have found to solve this problem, is actually to create a stored procedure with a dummy input parameter, so instead of using the stored procedure described above, customer actually had this kind of stored procedure:
CREATE PROCEDURE [dbo].[usp_GetCodesWithDummyInput]
— Add the parameters for the stored procedure here
@Dummy nvarchar(100)
AS
BEGIN
— SET NOCOUNT ON added to prevent extra result sets from
— interfering with SELECT statements.
SET NOCOUNT ON;
SET XACT_ABORT ON;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
— Insert statements for procedure here
SELECT Code
FROM Codes
END
Note: This is the only approach that uses a different stored procedure, all the others approaches are using the first stored procedure described in this post, i.e., without any input parameters ([dbo].[usp_GetCodes])
The reason for them doing that is that now they can easily create a map to create the request message which is used to invoke the stored procedure, by simply dragging the input parameter to the Dummy element of the stored procedure.
To be fair, it is actually a simple and effective solution to solve this problem, but here are the reasons why you shouldn’t use this approach:
In general, although it is a simple solution to implement, is not the best way to address this kind of problems/requirements.
As you can probably imagine by the approach name that I gave, this will be an even worse implementation.
There are, at least, two ways to create a message inside an orchestration and the only thing in common that they have is that they need to be inside of the Construct Message shape:
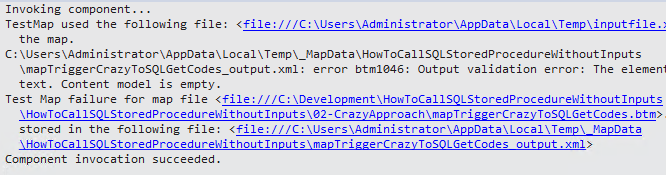
But some developers forget the second option, using Message Assignment shape, and because the request schema generated by the SQL adapter doesn’t have any inputs, as expected, it will be very strange and confusing for a BizTalk developer to use this kind of schemas in a map.
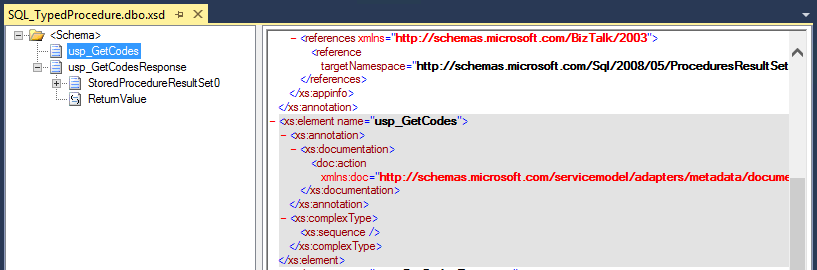
However, this does not disable or discourage them to innovate! And in some scenarios, I saw this kind of maps being created and used:

In the absence of an element to map from source to destination, and because the map requires at least one mapping rule inside, they map one of the element from the source to the root node in the destination schema.
So, why you should avoid this approach:
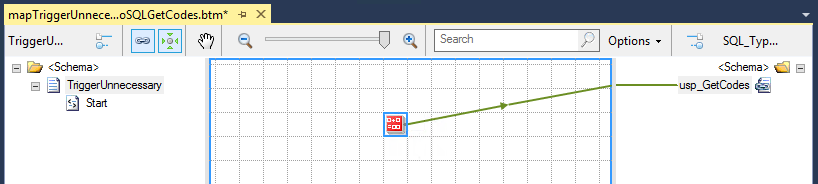
This approach is actually very similar to the previous approach, the crazy approach, but in a smart way! A way that I never imagined to use, to be honest, but that can be helpful in some situations.
Everything is exactly the same as the previous approach, but instead of mapping a random element for the source schema to the root name of the destination schema, which will generate an invalid message,iIn this approach, we are:
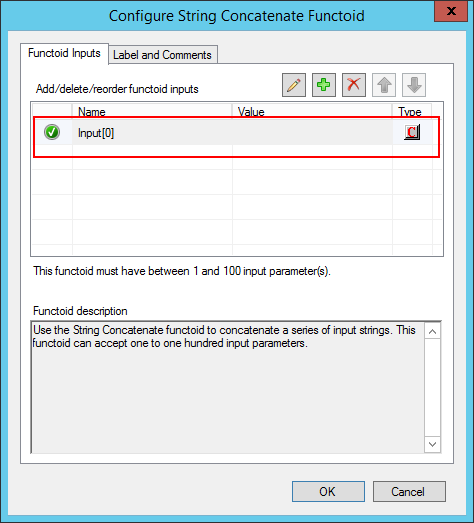
And surprisingly, this does the trick and it will generate a valid message:
<ns0:usp_GetCodes xmlns:ns0=”http://schemas.microsoft.com/Sql/2008/05/TypedProcedures/dbo” xmlns:ns3=”http://schemas.microsoft.com/Sql/2008/05/ProceduresResultSets/dbo/usp_GetCodes” />
So, why you should use this approach:
The only situation I can imagine this approach being useful is when we are creating this type of scenarios using Content Based Routing, i.e., without any kind of orchestrations but, until now, I never encountered this requirement.
I will not address this approach, but I think you may encounter that a lot, by using a helper class library to invoke the SQL Stored procedure using C# code.

And finally, we arrive to what, in my personal opinion, is the best or most correct solution to accomplish this task.
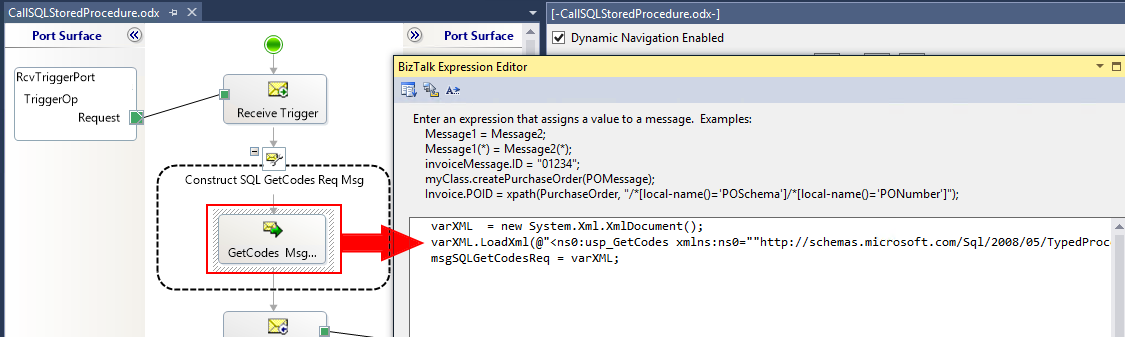
So, if you were following the post carefully, you may have noticed that in all the previous solutions we have used a map to generate the SQL Stored Procedure request message and we already saw why that is not the best approach. In this approach, what we will be doing is using the Message Assignment shape, instead of the Transform Shape (map), with the support of inline .NET code to create the request message.
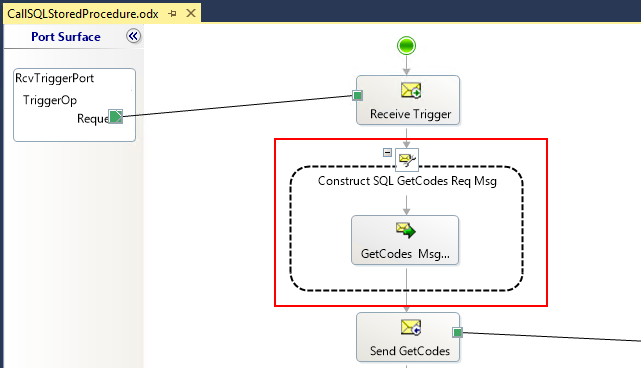
So, for that we will also need to create a support variable in the orchestration:
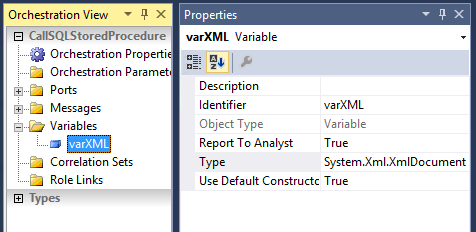
We will be using this variable to manipulate the creation of the SQL request message.
The next important thing is to actually have a proper sample of the SQL request message and for us to easily achive that we can go to the schema generated by the WCF-SQL adapter, normally something like “TypedProcedure.dbo.xsd”, right-click and choose Generate schema.
Of course, sometimes is not that easi, sometimes we have several stored procedures calls, that will handle several operations like: inserts, deletes or selects. And sometimes, when we try to generate a schema instance, it will not generate the message that we want. In that cases, you need to open the schema in the Schema Editor:
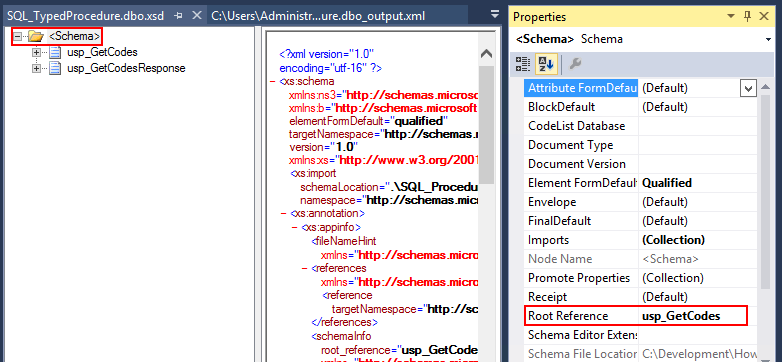

Note: if you want, you then can revert the “Root Reference” property to “Default”.
Now you just need to copy this XML sample and place it inside the Message Assignment shape, with support of our variable that we created previously, something like this:
varXML = new System.Xml.XmlDocument();
varXML.LoadXml(@”<ns0:usp_GetCodes xmlns:ns0=””http://schemas.microsoft.com/Sql/2008/05/TypedProcedures/dbo”” /> “);
msgSQLGetCodesReq = varXML;
Why is this the best way for me?
You can find all the source code here: BizTalk Server: How to call a SQL Stored procedure without inputs