Welcome again to another BizTalk Server Best practices, Tips, and Tricks blog post! In my previous blog posts, I discussed some essential tips and tricks for BizTalk Server administrators:
And for BizTalk Server Developers:
Today I will speak about another critical Best practice, Tips, and Tricks, this time for BizTalk Server developers: Understand Orchestration Persistence Points.

Understand Orchestration Persistence Points
Often ignored but really important if you are working with BizTalk Server Orchestrations, persistence points are a key issue/topic in dealing with Orchestrations performance.
But before we go deep into this topic, it is important to understand: what is a persistence point?
A persistence point is the process of saving your running orchestration state at a certain point in time. That means that the orchestration engine saves to persistent storage (BizTalk databases – BizTalkMsgBoxDb), at certain points, the entire state of a running orchestration instance so that the instance can later be completely restored in memory.
Persistence Points induce latency in BizTalk Orchestrations. Though you cannot avoid them, understanding them would help in using them efficiently.
By default, the orchestration engine saves the state of a running orchestration instance at various points or circumstances:
- At the end of a transactional scope is reached.
- The engine saves state at the end of a transactional scope so that the point at which the orchestration should resume is defined unambiguously and so that compensation can be carried out correctly if necessary.
- The orchestration will continue to run from the end of the scope if persistence is successful; otherwise, the appropriate exception handler will be invoked.
- If the scope is transactional and atomic, the engine will save the state at the end of the atomic scope when it commits.
- If the scope is transactional and long-running, the engine will generate a new transaction and persist in the complete state of the runtime when the scope completes.
- Once a debugging breakpoint is reached.
- When a message is sent.
- The only exception to this is when a message is sent from within an atomic transaction scope.
- When an orchestration starts another orchestration asynchronously, as with the Start Orchestration shape.
- Note: Call orchestration shapes do not cause persistence points
- When an orchestration instance is suspended.
- When the orchestration engine is asked to shut down.
- When this happens, the orchestration engine will try to save control information, as well as the current state of all running orchestration instances, so that it can resume running them when it is started again.
- If the engine is unsuccessful in saving the current state, the engine will resume the orchestration instance from the last persistence point that occurred before the shutdown. This applies to the system shutdown in controlled conditions and abnormal termination.
- When the engine determines that the instance should be dehydrated.
- And when the orchestration instance is finished.
- When the system shutdowns in a controlled manner.
If the engine must rehydrate the orchestration instance, start from a controlled shutdown, or recover from an unexpected shutdown, the engine runs the orchestration instance from the last persistence point as if nothing else had occurred.
Performance and persistence point
Simply put, the fewer persistence points in your orchestration, the faster it works. Each persistence point hits the database to store the current instance state.
The state includes:
- The internal state of the engine, including its current progress.
- The state of any .NET components that maintain state information and are being used by the orchestration.
- Message and variable values.
So, it is not rocket science that minimizing the number of persistence points when developing your solution will guarantee scalability, throughput, and low latency. Of course, we cannot avoid such a nice feature completely in your orchestration – yes persistence in specific scenarios is an excellent feature – but we can avoid them or minimize them following a few tips:
- We can reduce database round trips using an atomic scope.
- Any persistence point inside the atomic scope is serialized only at the end of the scope.
- Splitting your orchestration with multiple atomic scopes will minimize the number of persistence points.
- The performance of orchestration is really degraded when you send more than 500 messages to the external system using a send-shape loop without an atomic scope.
- Do remember the atomic scope is also serialized at the end.
- You can use the Call Orchestration shape instead of the Start Orchestration shape.
- You can use C# helper classes to perform certain business logic parts.
All object instances that your orchestration refers to directly or indirectly (as through other objects) must be serializable for your orchestration state to be persisted. There are two exceptions:
- You can have a non-serializable object declared inside an atomic transaction. You can do this because atomic scopes do not contain persistence points.
- System.Xml.XmlDocument is not a serializable class; it is handled as a special case and can be used anywhere.
Caution: For a .NET object to be persisted, it must be marked as serializable.
Persistence Point exercise
In the old days, Microsoft presented this small proof-of-concept:
- Consider an orchestration scenario with two send shapes sending messages to two different systems.
This can be implemented in the following ways:
- A) A parallel branch that has two Send shapes.
- B) Two send shapes being executed sequentially in the orchestration.
- C) Two send shapes being executed sequentially in the atomic shape.
Which of these three scenarios do you think would work the fastest?
And the answer is, without doubt, scenario C.
- The send shapes are enclosed in the atomic shape, and hence the state is persisted only at the end of the atomic shape.
- If it is at the end of the orchestration, the persistence point will be batched with the persistence point at the end of the orchestration. Hence resulting in a single persistence point.
Scenario B is out of the question because:
- The two Send shapes will have their persistence points. If the Send shape is the last shape in the orchestration, then the persistence point of the Send shape at the end of the orchestration will be batched together to result in a single persistence point instead of two.
With scenario A, even though we have the parallel branches in place, BizTalk, by default (feature by design), executes them in a sequential manner.
- Parallel branches do not necessarily mean they are executed on separate threads. Hence, even in this case, it results in sequential execution with two persistence points. In fact, in this case, the persistence point will not be batched at the end of the orchestration, resulting in the slowest of the three.
Hence, when designing the orchestration from the performance perspective, it is imperative to take a look at what points the orchestration will be persisting in the data. Reducing the database round trips helps increase the performance of the orchestration. But sometimes, especially if low latency is not a requirement and delivery is, we can also increase the number of persistence points.
Another way to minimize performance issues is to avoid the orchestration engine dehydrating your Orchestrations.
- Dehydration is the process of serializing the state of an orchestration into a SQL Server database.
- Rehydration is the reverse of this process: deserializing the last running state of orchestration from the database.
The orchestration engine might determine that an orchestration instance has been idle for a relatively long period of time. It calculates thresholds to determine how long it will wait for various actions to take place, and if those thresholds are exceeded, it dehydrates the instance. This can occur under the following circumstances:
- When the orchestration is waiting to receive a message, and the wait is longer than a threshold determined by the engine.
- When the orchestration is “listening” for a message, as it does when you use a Listen shape, and no branch is triggered before a threshold determined by the engine.
- The only exception to this is when the Listen shape contains an activation receive.
- When a delay in the orchestration is longer than a threshold determined by the engine.
- The engine dehydrates the instance by saving the state and frees up the memory required by the instance. By dehydrating dormant orchestration instances, the engine makes it possible for many long-running business processes to run concurrently on the same computer.
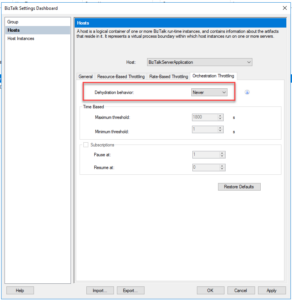
You can set 12 properties to configure how dehydration works in BizTalk Server. However, in certain cases, we can configure to never dehydrate by configuring the Dehydration behavior property to Never on the Orchestration Throttling tag of the Host settings.
Stay tuned for the following BizTalk Server Best practices, Tips, and Tricks.
